Building the Open Analytical Infrastructure to Accelerate Lab-to-Market Commercialization
By Jesse Lou, Rosie Keller, Teasha Feldman-Fitzthum
·······
Every year, thousands of scientists embark on the lab-to-market journey with strong technical conviction and years of deep domain expertise. They're expected to lead teams, raise capital, and continuously make hard prioritization and go/no-go decisions. The one question they're rarely well equipped to answer is the one that determines their eventual, real-world impact: is this technology commercially viable?
The tool that should anchor that question and inform those core commercialization decisions is techno-economic analysis (TEA): a structured way to evaluate commercial viability by understanding what drives cost, identifying where uncertainty lives, and helping connect R&D choices to commercial outcomes. The value isn't just the TEA as an artifact, it's the thinking that developing the artifact forces: when scientists build a TEA, they develop the intuition they need to navigate the hardest decisions in commercialization. And yet:
An Ecosystem-Scale Problem Driven by Individual Team Barriers
Underutilizing TEA isn't just a problem for individual teams. It's a gap that compounds into a systemic failure at ecosystem scale.
There are roughly 40,000 early-stage climate teams and 500,000 applied researchers globally, backed by over $100B in public R&D and private capital. From a climate perspective, these technologies only matter if they reach scale, and that capital flows with the expectation that good science will find its way to deployment. But when most teams struggle to evaluate their own economics, too many viable technologies stall and too many scarce time and capital resources are misallocated to false positives.
Why Teams Get Stuck
Over 2,000 hours of coaching 80+ early-stage teams, we've observed a consistent set of patterns that explain why TEA adoption remains so low — even among teams that understand its importance.
TEA is inaccessible
TEA is seen as a complex, high-precision academic exercise requiring specialized software, months of effort, and niche expertise. When a scientist opens a TEA template or existing model and sees a VBA-heavy Excel model with fifteen tabs of multi-colored tables and unfamiliar acronyms, many close it and go back to the lab. What makes this especially costly is that the perception of required precision is wrong: early-stage TEA should be directional, designed to surface unknown unknowns and provide a framework for addressing them. The resulting cold-start problem is real, and each analysis is inherently idiosyncratic, but the accessibility bar is lower than it looks.
Trust is hard to build
Even when teams get started, they struggle to build enough confidence in their analysis to actually make decisions based on it. The issue is two-fold: trusting that the model itself is sound, and trusting the underlying input data. Without confidence in their assumptions and whether they aptly apply to their specific context, teams hesitate to internalize the analysis, delaying or avoiding taking the steps that move the needle: grappling with sensitivities to inform R&D priorities, driving discovery, and communicating their economics to investors and partners with conviction and credibility.
The data bottleneck delays commercial viability conviction by months
In a best-case scenario — concerted effort, minimal additional research — a team can build a solid first-pass TEA in 20–25 hours. Yet teams routinely take months to get there, because every assumption becomes a mini research project. What does a commercial-scale electrolyzer actually cost? Am I missing a critical unit operation? Is this yield assumption reasonable, or am I off by an order of magnitude? Each question can mean days of searching across scattered reports, academic papers, and vendor quotes, and those hours spent hunting for data don't compound. A founder who spends weeks tracking down electrolyzer cost ranges and getting quotes hasn't learned anything meaningfully new about their own technology or the industry they are deploying into. That real learning happens in model building: understanding how processes connect, stress-testing assumptions, and running sensitivities. The data search itself quickly becomes inefficient overhead.
Individualized TEA support is effective, but doesn't scale
We've seen what happens when teams get personalized support through our past TEA coaching work. Like driving school vs taking an Uber, when founders build the model with their own hands, they develop a deep understanding of their technology and its deployment path. This empowers them to build the conviction required to dedicate years of their lives to commercialization, or to accept hard truths about their economics.
However, one-on-one TEA coaching relies on expert time and is impossible to scale.
Massive redundancy at ecosystem scale
The lost time and effort on data collection and validation compounds massively at ecosystem scale. A team in Cambridge and a team in Singapore independently spend weeks hunting down and building conviction in the same process flow or data point, while an expert could have gut-checked that figure in five minutes. They know which sources to trust, what ranges are reasonable, and when something feels off. When that expert validation happens once and is made accessible, it serves every team that will ever face the same question, collectively redirecting millions of precious hours back to science and translation efforts.
Our Thesis
TEA Commons aims to turn techno-economic analysis from a bespoke, inaccessible exercise into democratized, empowering practice through a combination of public goods that hundreds of thousands of entrepreneurial scientists, and any of the institutions that support them, can build on.
Before GPS, every driver navigated alone: buying paper maps, printing MapQuest directions, asking strangers, making time-consuming wrong turns. The roads existed, but what was missing was a shared navigation layer that made them usable by anyone new to the area. Climate commercialization is at the same inflection point. The industrial data exists, but it's scattered and opaque, and every team drives around wasting time on wrong turns. What's missing is the shared analytical infrastructure to make all their journeys easier and faster: the maps, the tools, and the people who keep them current. TEA Commons is building that infrastructure. But unlike navigation apps, the goal isn't to let the driver stop thinking about the roads, it's for the scientist to stay at the wheel and arrive knowing the territory.
No existing resource combines validated data with support idiosyncratic enough to serve each team's unique technology. TEA Commons is built around three mutually reinforcing pillars:
- Validated Data as the map layers that ground every analysis in referenceable, expert-checked sources.
- AI-Enabled Tooling as the turn-by-turn navigation that adapts shared infrastructure to each team's specific route.
- And a Human Network of practitioners and partners — the locals who know the roads and keep the maps current, whose leverage is multiplied by good infrastructure.
What We're Building
Pillar 1: Data — The Map Layers
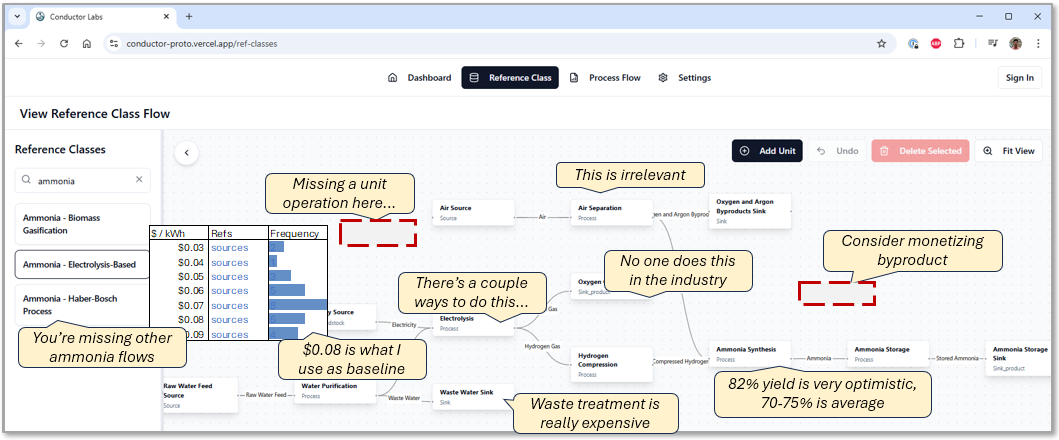
Any novel technology, almost without exception, deploys at least partially into one or several of the roughly 500–600 major reference classes globally: the established and emerging industrial processes that breakthrough technologies slot into, displace, or recombine. We pre-build each reference class once and validate it with experts — so any team's TEA becomes an act of assembly: matching their technology to the closest class or combination of classes, customizing where their approach diverges, and building from a validated baseline rather than from scratch.
The repository covers all major climate-relevant industries: roughly 20–25 verticals, each containing 30–40 sub-industries or process configurations. Within each, using process flow diagrams as the scaffold, we collect and validate the process and economic data an entrepreneurial scientist needs to build a TEA: raw material costs, capex benchmarks, performance ranges, process yields, product specifications.
For each data point, we target rough accuracy: ±30% ranges aggregated from public sources and validated by domain experts. This is the precision early-stage teams actually need — enough to identify which parameters drive outcomes, where to focus R&D, and which questions deserve more scrutiny — and it's fast for experts to provide without hitting proprietary constraints, which is what makes validation viable at scale.
Even before any AI interface is added, the repository has standalone value: a searchable, validated reference for industrial process economics that serves teams directly and stays useful however the tooling evolves.
Like mapping the main thoroughfares first, we build the 20% of data that unlocks 80% of the value — the highest-impact reference classes that recur across teams and verticals — delivering substantial value long before the full repository is complete. Validation compounds the same way: parameters like electricity prices, compressor capex, and separation costs recur across dozens of reference classes, so a value confirmed in one vertical strengthens confidence everywhere it appears, and models benchmarked in one industry help triangulate data in adjacent ones. Each expert-hour serves not one reference class, but every class that shares its data. In aggregate, the repository will contain millions of data points, continuously improved as users submit feedback and experts refine validation.
Pillar 2: Tooling — Turn-by-Turn Navigation
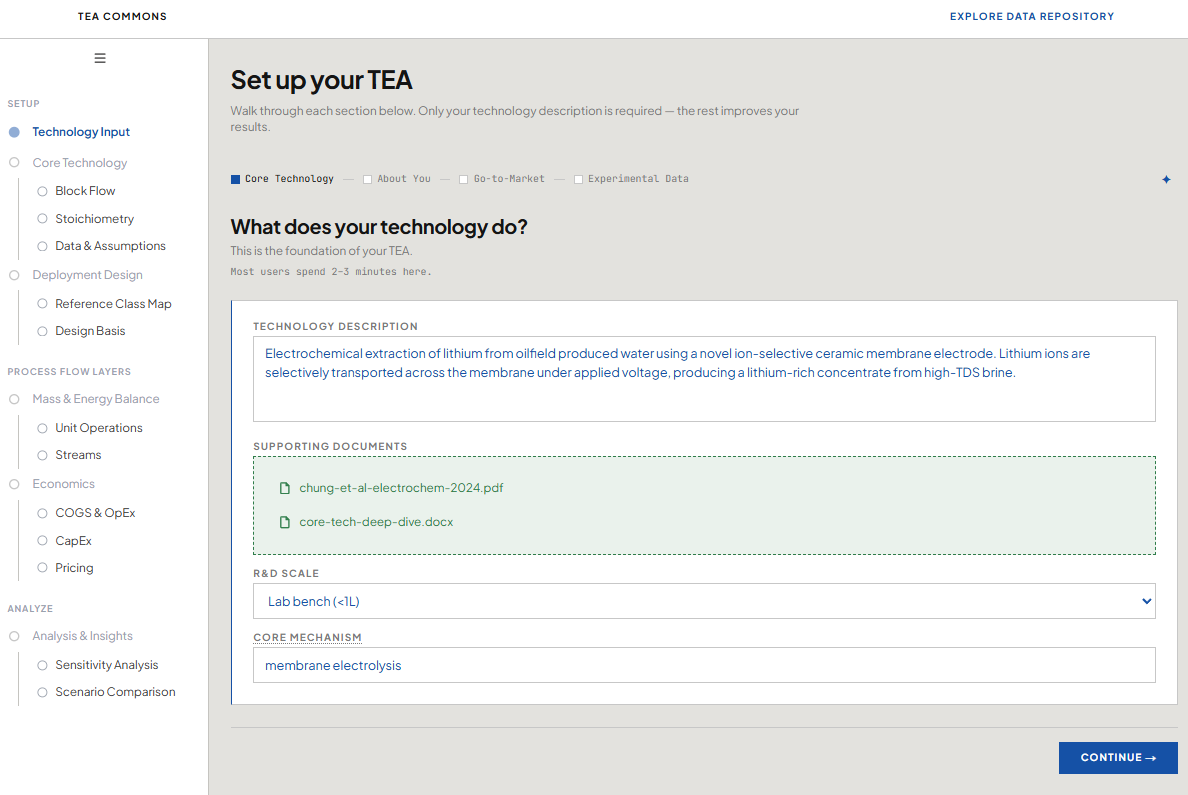
The AI co-pilot guides teams from a blank sheet to a working model. It supports them with mapping process flows, surfacing relevant data from the repository, walking through a step-by-step framework tailored for early-stage teams based on our coaching insights, and flagging where assumptions need scrutiny. It adapts to each team's technology and stage, meeting teams where they are.
The goal isn't just a completed, actionable TEA — it's a scientist who deeply understands their own economics, multiplied across thousands of teams. Credible teams that will be successful in the long-run can defend every assumption, know which to revisit first, and can make changes to the model as their understanding evolves. The co-pilot is designed accordingly: it asks questions rather than producing answers, surfaces the reasoning behind every data point, and deliberately adds the productive friction that keeps the scientist in the driver's seat. This ensures the TEA isn't just a document, but becomes a lasting mental model.
Underneath the co-pilot sits a TEA calculation engine, a core analytical layer that ensures numerical rigor independent of the LLM. This engine also unlocks use cases beyond individual team TEAs: it can support scalable IP evaluation, white space identification, and portfolio-level analysis for investors and program managers.
Pillar 3: Network — The Locals Who Know the Roads
Even the best navigation system benefits from people on the ground. The Network pillar expands the coalition to include two inter-related roles.
Industry experts and TEA practitioners: TEA practitioners and industry veterans are the validation backbone of the data repository. An electrochemist who has designed commercial-scale PEM systems can gut-check an electrolyzer capex assumption in minutes and assign a confidence score that makes that data point useful for thousands of teams.
The exchange goes both ways. TEA practitioners gain a platform for thought leadership and insight-sharing that builds visibility with the next wave of climate teams, and a natural pipeline for their consulting work. They also plug into a community of peers where learnings, methods, and hard-won judgment travel freely, turning what is still largely isolated expertise into a shared professional space.
Boots on the ground: accelerator mentors, research program managers, and other ecosystem teams are so often the human-in-the-loop for early-stage founders. They know their teams deeply and are often the first call when a team needs support. The TEA Commons gives these partners better infrastructure: validated data to reference, tooling to point founders toward, and a community where questions get answered.
Our Approach to AI
Our main objective is to close the TEA adoption gap, accelerating the deployment of impactful climate technologies. TEAs that aren't trusted won't get used. To ensure trustworthy outputs and confident application of TEA, we make deliberate system design decisions around the use of AI.
Our principles:
Every number is auditable. Inputs are sourced, cited, and inspectable: every number traces back to a hardcoded datapoint from a trackable source, or is calculated through deterministic formulas. AI surfaces values; it does not generate them.
The math is deterministic. We minimize the surface area of AI-derived input. Models are fixed systems of equations — like a robust spreadsheet, the same inputs always produce the same outputs. AI may help assemble a model, but its output is always explicit equations that can be inspected line by line.
Canonical process flows as the foundation. The system anchors in the library of validated reference industrial processes. Novel technologies are handled by identifying the closest reference class and customizing from there, which keeps the probabilistic surface small and the auditable surface large.
How We Use AI
We use AI in two distinct roles: one on the building side of the TEA Commons, one on the user side.
Building the TEA Commons: data collection and validation. AI systematically surfaces relevant data points across sources for a given reference class, identifies where values converge or diverge, flags outliers against expected ranges, and structures raw material into the repository schema. For expert validators, it streamlines the review cycle: they review every data point, but anomalies are flagged and data ranges are refined in custom-built workflows.
Using the TEA Commons: idiosyncratic guidance. Every technology is different, and each scientist has a different starting point. One of the most valuable supports a scientist can get is guidance that accounts for the specifics of their process, stage, and context. AI makes that possible at scale. It matches a team's novel technology against the reference library, surfaces the closest process flow, flags where their solution diverges, and walks them through model construction by asking the questions a TEA coach would ask. The result is personalized, adaptive guidance that one-on-one coaching could never cost-effectively deliver to thousands of teams.
The goal of both is the same: make expert-intensive work faster and more accessible, without displacing the judgment that experts and scientists have to provide.
Why It Matters
When a founder can show credible economics early, almost every downstream commercialization outcome improves: sharper R&D priorities, better targeted market discovery, more convincing investor and partnership conversations. At ecosystem level, the gains compound. Millions of hours now lost to data-hunting return to R&D and deployment, and capital, talent, and policy move toward climate impact faster, with more conviction, and with less friction (see theory of change on the right).
The barrier to TEA adoption is not motivation. Scientists, investors, and program managers all recognize the value of right-sized early-stage economics. The problem is that doing TEA well is hard, data is scattered, and adoption doesn't scale without shared infrastructure. Building analytical TEA infrastructure as a public good enables more efficient allocation of time & capital across the ecosystem and a common analytical language for innovators, funders, incumbents, and policymakers.
Our thesis for the flywheel: if the data and tooling deliver real value, adoption compounds. Teams will find our resources organically, programs will push cohorts to use them, and experts and incumbents will contribute data in exchange for access to a stronger pipeline. The same dynamic that made open infrastructure like PubChem foundational to modern biology can work here, with each cycle of contribution and use drawing in the next wave of participants, and the TEA Commons becomes an enabling layer for the entire ecosystem.
Why Now, and Why This Team
The conditions for solving the scalable TEA data and guidance problem have changed. AI has matured to the point where it meaningfully accelerates the most labor-intensive parts of the work: extracting and structuring data from scientific literature and compressing the expert validation cycle. However, the main challenge, data collection and validation, is still largely operational and that work is tractable today, but it requires sustained, coordinated execution, not new breakthroughs.
Our team brings direct experience across every dimension this effort requires.
- On TEA: we've worked across the full lab-to-market lifecycle, from pre-spinout research teams to late-stage project finance, including three years leading fusion economics at Commonwealth Fusion Systems and over 2,000 hours of hands-on TEA coaching.
- On early-stage support: we've scaled dozens of entrepreneur support programs across emerging markets to hundreds of founders through Seedstars and Newlab, and bring deep experience from several years at Breakthrough Energy Fellows.
- On software and AI: our backgrounds include MIT CSAIL research commercialized into ML-based wind resource assessment (acquired) and building AI for actuarial modeling at Cyence.
- And across industrials: we bring pattern recognition from McKinsey (oil & gas, chemicals, mining, infrastructure), Breakthrough Energy Fellows, and ARPA-E (blue-tech and CDR ecosystem mapping).
We already have a supportive coalition of 50+ partners across academia, government, accelerators, and investors, including Breakthrough Energy Fellows, MIT, Undaunted (Imperial College), Oxford, LSU, and Homeworld.
Join Us
The TEA Commons is designed to be accessible to every climate scientist, every research institution, and every ecosystem enabler — regardless of geography, stage, or resources.
Funders: We're seeking non-dilutive capital to fund the data build-out and tooling development — an investment in public goods that increases the leverage of every downstream dollar spent on climate innovation. If you see the opportunity in building shared analytical infrastructure, we'd love to talk.
Research institutions and ecosystem enablers: We're looking for pilot partners who will push their teams to adopt TEA and contribute domain expertise for specific verticals. If you support early-stage climate teams through accelerators, incubators, or lab-to-market programs, there are concrete ways to work together.
Practitioners and domain experts: The data repository is only as good as the people who validate it. If you're a TEA practitioner or industry veteran who believes in this field, we're building a community for you — one where your expertise reaches thousands of teams instead of a handful.
Industry and incumbents: Your operational data and process knowledge can dramatically accelerate the quality of the repository. In return, a stronger analytical baseline across the ecosystem means a higher-quality pipeline of technologies and teams reaching your door.
We'd be grateful to have you alongside us.